






Key Takeaways:
LLMs are advanced AI models that help businesses automate tasks, improve decision-making, and deliver more human-like interactions.
Choosing the right LLM type allows teams to balance cost, speed, and domain accuracy, helping them build smarter apps with predictable performance.
Custom LLMs offer full control, stronger data governance, and tailored behavior for sectors with sensitive information or unique operational needs.
Common LLM types include base, instruction-tuned, PEFT, domain, and multimodal models.
The step-by-step LLM model development starts with defining goals, behavior rules, and key metrics.
Industry-specific LLMs enhance precision for healthcare, finance, legal, retail, and manufacturing.
The cost to develop an LLM model ranges from $30,000 to $450,000 and more, depending on project requirements.
Common LLM development challenges include high compute cost, weak data quality, and safety issues.
PEFT methods, strong data pipelines, and structured alignment can be used to overcome identified challenges.
Continuous monitoring and improvement cycles keep the LLM safer, more reliable, and better aligned with evolving business needs over time.
Technology feels smarter today. We chat with apps, get instant answers, and see tools write or solve tasks for us. Behind this shift is a new type of AI system trained on large volumes of text and data.
Many people know about it, but fewer understand how it works or how a business can build one that fits its needs.
This system is called a Large Language Model. It helps applications understand text, respond naturally, and support real business tasks. As interest grows, more teams are exploring how to develop an LLM model to improve automation, protect data, and build smarter products.
Creating an LLM model follows a clear process. It starts with defining a goal, gathering and cleaning data, selecting an algorithm such as neural networks, training the model, evaluating results, fine-tuning accuracy, and deploying it. Depending on goals and model size, this journey can take months or longer.
In this blog, we will help you understand “How to create an LLM model” in simple steps. By the end, you will have a clear idea of what goes into development and how your business can benefit from it.
What Are LLM and LLM Models?
A Large Language Model is a form of artificial intelligence and is among the key AI trends that learns patterns, meanings, and relationships from text. It has the ability to read huge amounts of written data like books, articles, code, and messages.
Over time, it learns how people write, ask questions, and share ideas, based on which it responds in ways that feel natural and useful. A key aspect worth noting is that the LLM models do not think like a human. It predicts what should come next based on everything it has learned from the pre-feed or procured data sets.
Today, LLMs are used in almost every field, and you can also plan to develop an LLM model as per your operational requirements.
From analyzing documents to supporting hospitals in decision-making, to assisting students with learning, and helping companies manage customer service, LLM models can do it all.
Businesses often build or customize LLM models to fit their industry needs, improve accuracy, or protect private data. It can speed up work, solve problems, and uncover insights from large information sets.
When trained well, a custom LLM development becomes a reliable partner that makes apps feel more human and more helpful.
Key Components of LLM Models
If you want to know about “How to develop an LLM model?” then you need to be aware of the multiple technical elements or components of LLM.

Each one shapes how the model learns, processes text, and produces meaningful output.
1. Tokenization Layer
LLMs cannot read plain text, so tokenization breaks words and phrases into numerical units called tokens. Hence, it acts as a key component of LLM Models.
A strong tokenizer handles rare terms, multi-word expressions, and domain phrasing effectively. Better tokenization leads to richer understanding and improved memory efficiency.
2. Embedding Layer
Once tokens exist, they must be mapped into dense vectors through embeddings. These vectors encode meaning and similarity, allowing the model to interpret context, tone, and the relationship between tokens.
Hence, when planning to create an LLM model, it is important to ensure high-quality embeddings so that they can help improve reasoning and retrieval tasks.
3. Transformer Blocks
This is the computational engine of modern LLMs. Transformer blocks contain self-attention units, feed-forward networks, residual connections, and normalization layers.
They enable the model to analyze sentence structure and text sequences, which is why transformers dominate custom LLM development.
4. Positional Encoding
Since transformers read tokens in parallel, positional encoding injects word order and sentence flow back into the network.
This allows the LLM model to understand grammar, sequence logic, and dependency patterns. Hence, it is one of the key components to be focused on when planning to build your own LLM.
5. Attention Mechanism
An attention mechanism helps the model selectively focus on important parts of the input while ignoring irrelevant details.
Such a component is one of the most important components in the LLM development process, as it improves long context processing, reasoning, and conversation quality because the system learns what matters most.
6. Output Projection Layer
After processing, internal representations are projected into token probabilities, selecting the next word or phrase. This is one of the common layers that needs to be focused on when you build an AI app.
Hence, the output projection layer directly controls text generation quality and fluency. Such is one of the key components, because it helps the model to interact with the audience.
7. Parameter and Memory Storage
LLMs learn through billions of weights stored within the network. But what to use and where is decided based on the parameters.
These parameters capture language patterns, domain rules, and task behavior, and are modified during training or tuning. Hence, even in the private LLM development, focusing on such a component is significant for the successful working of the LLM model.
8. Inference Optimization Layer
Such a layer acts as a middle layer between the user and the LLM model, performing caching, batching, and decoding in real-time to ensure model efficiency.
This layer keeps latency predictable and assists in the scalability of the LLM models.

Types of LLM Models
Along with focusing on “How to create an LLM model?”, you must also be aware of what are the types of LLM Models.
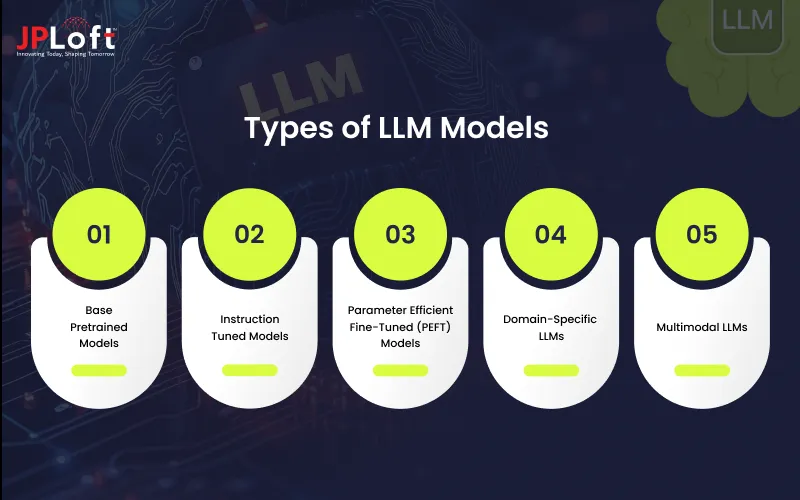
Understanding these types helps teams plan architectures, cost models, and tuning methods before they build an LLM model or extend an existing one:
Type 1: Base Pretrained Models
These are large foundation models trained on massive public datasets that cover general knowledge. They include GPT-style models, Llama, Falcon, MPT, and Gemma. They learn grammar, reasoning patterns, and context relationships, but are not specialized for any task.
Developers often select them as a starting point when learning how to make an LLM model because they reduce the need to train from scratch.
Type 2: Instruction Tuned Models
Another LLM model to be aware of is the instruction-tuned models. These models are optimized to follow prompts better. They are refined using supervised training and reinforcement learning signals.
Examples include apps like ChatGPT variants, Llama 2 Chat, and Zephyr. These models understand role instructions, apply safety rules, and give structured answers. They are used in enterprise chatbots, workflow assistants, and Q&A systems.
Type 3: Parameter Efficient Fine-Tuned (PEFT) Models
PEFT models rely on lightweight tuning methods like LoRA, QLoRA, prefix tuning, and adapters. Teams update only small subsets of parameters, rather than retraining full weights.
This reduces time and cost when developing LLM models and ensures convenient updates for the models. PEFT is common in custom LLM development, where firms add industry knowledge while keeping compute demand low.
Type 4: Domain-Specific LLMs
These models focus on one field. They train on specialized texts such as legal files, medical journals, manufacturing logs, or banking documents. Examples include MedPaLM, BloombergGPT, and FinGPT.
They deliver higher accuracy because they learn vocabulary and reasoning patterns unique to each sector. Industries use them for compliance, analysis, and decision support.
Type 5: Multimodal LLMs
Multimodal LLM models can understand and generate across more than text. Examples include GPT 4 and Gemini, which process images or audio with text.
These models power document parsing, voice agents, vision reasoning, and multimedia assistants. They are useful for companies that want to develop an LLM model that manages richer inputs or user experiences.
Which Is Better: Custom LLM or Fine-Tuned Model?
When companies plan how to develop an LLM model, they usually have two paths to choose from:
One is to train a brand-new custom model, and the other is to fine-tune an existing one. Both paths have their implications, and they support business goals, but they differ in cost, time, complexity, and control.
1] Custom LLM Development
If you choose a custom LLM development, then it needs to be trained from scratch using your own datasets and model design. You control everything from tokenization to architecture choices and training rules.
This option fits large enterprises, research labs, and organizations with strict privacy rules or unique needs.
2] Fine-Tuning Existing Models
Fine-tuning approach updates a pretrained model like GPT, Llama, Falcon, or Mistral instead of training from scratch. The base model already knows language structure and reasoning.
As a developer, your task is to adopt the step-by-step LLM model refinement to your industry through supervised training, reinforcement learning, or parameter-efficient tuning methods such as LoRA or QLoRA.
This route works for businesses that want domain value without high cost. It is faster, budget-friendly, and suitable for private deployments.
|
Technical Dimension |
Custom LLM Development |
Fine-Tuning Existing Models |
|
How the Model Is Built |
The model is trained from scratch following a full step-by-step LLM model pipeline |
Pretrained models are adapted using a focused LLM development process |
|
Base Model Usage |
No base model is used; the architecture is designed internally |
Uses existing models like GPT, Llama, Falcon, or Mistral |
|
Tokenization Control |
Full control over tokenization, vocabulary, and embeddings |
Tokenization is fixed by the base model |
|
Training Approach |
Full pretraining, instruction tuning, and alignment stages |
Supervised fine-tuning, RLHF, or parameter-efficient tuning |
|
Tuning Methods |
Custom objectives and reward functions |
LoRA, QLoRA, and other efficient methods |
|
Compute and Infrastructure |
Very high compute needs with distributed GPU clusters |
Moderate computing with shorter training cycles |
|
Dataset Requirement |
Large proprietary datasets are required to build your own LLM |
Smaller, domain-specific datasets are sufficient |
|
Development Time |
Longer timelines when teams develop an LLM model from scratch |
Faster results when teams create an LLM model through fine-tuning |
|
Cost Impact |
High cost due to data scale, compute, and expert resources |
More budget-friendly for businesses |
|
Model Control |
Full control over architecture, behavior, and safety rules |
Control is limited to behavior and task adaptation |
|
Data Privacy |
Best suited for sensitive or restricted datasets |
Suitable for private deployment with some base model limits |
|
Best Fit Use Cases |
Healthcare, finance, defense, and research-heavy systems |
Chatbots, support tools, analytics, and internal automation |
3] How to Decide Between the Two?
Choosing between custom LLM development and fine-tuning depends on your data, budget, and long-term goals. Teams exploring how to build an LLM model should first assess data sensitivity.
Many teams start with fine-tuning to validate results and later move toward custom models as their requirements grow.
Step-by-Step LLM Model Development Process
Building an LLM is a large technical project, but it becomes much convenient when you understand the steps to develop an LLM model and the workflow is divided into a few main phases.
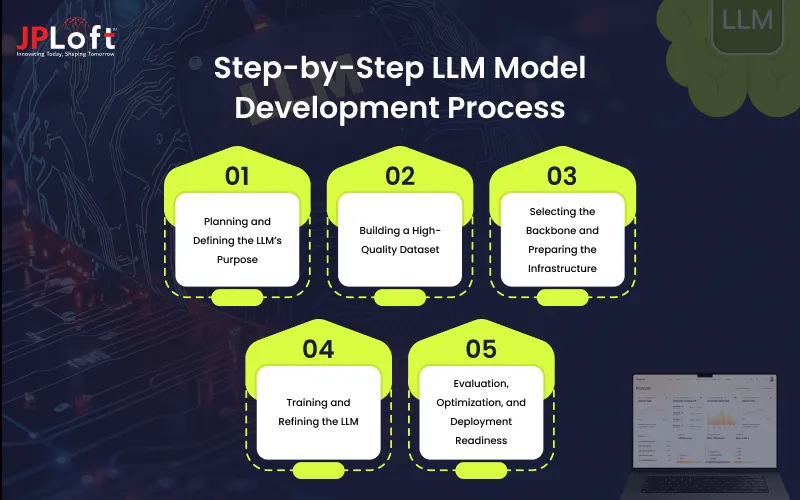
Within each phase, several tasks contribute to how the model learns, reasons, and performs. The following guide explains the full process teams follow when they build an LLM model for production use.
Phase 1: Planning and Defining the LLM’s Purpose
Every LLM development process begins with a clear purpose. Before training starts, teams define the exact task the model should solve. This could be answering questions, helping with research, analyzing documents, or powering a domain assistant.
Defining the purpose early prevents wasted compute and ensures the model is trained in the right direction.
► Behavior, Policies, and Output Rules
Once the priorities and goals are set, the teams are expected to describe the expected behavior. This includes the tone of responses, how strictly the model should follow instructions, and which topics it must avoid.
At this stage, safety rules are also defined, so the model does not generate harmful, biased, or misleading content.
► Choosing Metrics
To evaluate progress, the teams also choose metrics that can act as the benchmark for training quality and guide all technical steps that follow. Such metrics can include perplexity, accuracy, alignment quality, or latency.
These rules are important whether you are planning for a custom or a private LLM development.
Phase 2: Building a High-Quality Dataset
When planning to build your own LLM, focusing on a strong dataset is significantly important. The teams need to plan how to collect text from sources such as internal knowledge bases, manuals, support logs, research papers, or public datasets.
In some cases, synthetic data is generated to fill gaps and create consistent training examples.
► Data Cleaning and Structuring
Raw text or data is rarely used for training. Hence, at this stage, Developers clean it by removing duplicates, fixing formatting issues, normalizing structure, and removing unwanted or unsafe content.
The data is then broken into smaller chunks and tokenised, so the model can process it.
► Ensuring Training, Validation, and Test Splits
The dataset is divided into three sections. The training set teaches the model, the validation set guides tuning decisions, and the test set measures final performance.
Using version control, the developers ensure dataset consistency, and such an approach also makes it easy to compare multiple training runs.
Phase 3: Selecting the Backbone and Preparing the Infrastructure
Most teams start with a pretrained backbone such as Llama, Mistral, Gemma, or Falcon. These models already understand general language patterns.
Teams choose a size based on their budget and reasoning needs. Smaller models run faster, but may not perform well in complex tasks. Larger models offer stronger outputs but come with higher computational costs.
► Configuring Training Hardware
In the LLM development process, model training is another important aspect that requires a stable environment. Engineers set up GPU clusters, cloud nodes, or hybrid hardware.
Frameworks like PyTorch, DeepSpeed, JAX, or Hugging Face Accelerate help coordinate distributed training. Mixed-precision strategies reduce memory use, and checkpointing protects progress in long runs.
► Monitoring and Stability
As training starts, logs help track loss curves, GPU usage, memory pressure, and speed. A strong monitoring layer reduces the risk of failed runs and helps detect issues early.
Phase 4: Training and Refining the LLM
If the team decides to extend the backbone model, this step teaches the system a more general language or domain-specific context.
During pretraining, billions of parameters are updated as the model learns relationships, meaning, and structure. This step forms the model’s core intelligence.
► Supervised Fine-Tuning
Fine-tuning adapts the model to real tasks. Developers create example prompts and responses that match the model’s intended job. The model learns tone, structure, and domain behavior.
In many cases, LoRA or QLoRA reduces compute needs by updating only a small part of the model instead of the full parameter set.
► Instruction and Policy Alignment
Even with fine-tuning, the model may behave unpredictably. Alignment steps such as RLHF, DPO, or preference optimization help control behavior.
During alignment, the model learns to stay within safe guidelines, follow rules, avoid risky content, and acknowledge uncertainty when needed.
Phase 5: Evaluation, Optimization, and Deployment Readiness
Before deployment, engineers need to define the checklist that includes: what is required to create an LLM. Based on this, the model is tested across a wide range of prompts.
They check accuracy, reasoning patterns, hallucination frequency, safety behavior, and long-context understanding.
Domain experts review responses to verify real-world reliability. Stress tests determine how the system behaves under heavy load or challenging inputs.
► Optimizing for Real Use
Even strong models can be expensive to run. Teams use techniques like quantization, pruning, caching, and distillation to lower cost and improve speed.
These methods help the model run smoothly on GPUs or server clusters without losing too much quality.
► Preparing for Deployment
Once optimization is complete, the model is packaged into an inference server. This server manages requests, logs output, and adds extra safety layers.
Companies choose deployment environments based on privacy needs. Some models run in the cloud, while others use private servers or on-prem hardware for full control.
► Continuous Improvement Cycle
Deployment is not the final step. LLMs improve when teams collect feedback, refine datasets, and re-run tuning cycles.
Over time, the model becomes more accurate, safer, and better aligned with user needs.
How to Train Your Custom LLM Model?
Training a custom LLM is a common selection by developers planning to develop an LLM model to control both the time and the effort.

Here is a breakdown of the core stages involved when teams plan to train a custom LLM model.
Step 1. Define Objectives and Metrics
The first step is ensuring clarity. The teams need to document the model’s purpose, expected response behavior, user needs, safety rules, and latency goals.
At this step, they also need to finalize the evaluation metrics like perplexity, accuracy, or alignment scores to keep development tied to business outcomes.
Step 2. Build and Prepare Training Data
Once goals are set, dataset engineering begins in the process to create an LLM Model. Developers collect domain text from sources such as manuals, chat logs, knowledge bases, or synthetic generation.
The data is cleaned, tokenised, deduplicated, and split into training, validation, and test sets to support reliable measurement and reproducibility.
Step 3. Select Model Backbone and Size
Teams then choose a pretrained architecture like Llama, Gemma, Mistral, or Falcon. Model scale is balanced against reasoning needs and computational limits.
Selecting the right size is important because larger backbones improve output but increase GPU cost and latency, so choosing the right size is critical.
Step 4. Configure Training Infrastructure
Post selecting or deciding on the model backbone and size, it is important to plan for the training infrastructure. Engineers set up the computing ability of the LLM model using tools like PyTorch, DeepSpeed, or JAX.
The model tech stack includes GPU clusters, checkpointing, gradient accumulation, and monitoring to track loss curves, memory use, and training stability.
Step 5. Fine-Tune and Align Behavior
The model is adapted to the domain using supervised fine-tuning and alignment approaches such as RLHF or DPO.
In this process, the implementation of techniques like LoRA and QLoRA reduces resource demand and supports frequent updates.
Step 6. Evaluate and Iterate
Finally, the model is validated for quality, safety, hallucination behavior, and domain accuracy. This is the final stage involved when planning to create an LLM model.
The teams can further adjust data, parameters, or compression methods until the system is ready for deployment.
Industry-Wise Use-Cases of LLM Models (Including Examples)
LLM models are now embedded across industries to automate, analyze, and support complex workflows.
More businesses across industries are focusing on how to build an LLM model, as they are experiencing improved accuracy and reduced manual effort post-implementation of the model.
.webp)
Here are industry-specific examples.
1. Healthcare
Healthcare systems use LLMs for clinical notes, diagnosis support, patient queries, and automating workflows. When hospitals develop an LLM model tuned to medical language, it understands terminology, improves triage, and helps clinicians retrieve answers faster.
Example: Google MedPaLM is an LLM or AI in healthcare model that supports physicians with structured reasoning and reliable medical insights that improve care decisions.
2. Finance and Banking
Banks deploy AI in finance or LLMs for compliance checks, contract reading, regulatory automation, insights extraction, and fraud analysis. By customizing an LLM model with financial datasets, analysts speed up reporting and improve accuracy in interpretation.
Example: BloombergGPT helps research teams summarize filings, draft analyses, and process complex market information faster.
3. Legal Services
Law firms apply LLMs for contract review, drafting, case research, and due diligence. When legal teams build own LLM, it learns clause patterns, risk language, and precedent logic, helping lawyers review documents faster and spot issues.
Example: Harvey AI supports attorneys with discovery analysis and structured drafting tasks.
4. Customer Support
Support teams use LLMs for intent detection, triaging tickets, response generation, and knowledge search. Companies often fine-tune an LLM on service transcripts to maintain tone consistency and improve first-response accuracy.
Example: Intercom’s AI-powered assistant boosts support resolution speed using tuned transformer-based models.
5. Education
EdTech firms use LLMs or models supporting AI in education for personalized tutoring, automated grading, lesson generation, and student feedback. When institutes create an LLM model for academic use, it adapts explanations to learning style and speeds content creation.
Example: Khanmigo acts as an AI tutor offering topic breakdowns, guided learning, and practice exercises.
6. Software Engineering
Developers use LLMs for code generation, debugging, architecture suggestions, and documentation. Many organizations fine-tune an LLM model on internal repositories to maintain code style and improve productivity.
Example: GitHub Copilot speeds development by providing relevant code suggestions based on trained transformer models.
7. Retail and E-commerce
Retail companies deploy LLMs for personalized search, product conversation, demand forecasting, and recommendation engines. When merchants customize an LLM, shoppers receive contextual guidance and better discovery flows.
Example: Amazon’s internal LLMs or AI in Retail enhance search ranking, product Q&A, and conversational shopping experiences.
8. Manufacturing and Industry 4.0
Another industrial use case of LLMs can be found in factories and manufacturing institutions. They use LLMs or advanced AI in manufacturing for diagnostic support, maintenance logs, technician assistance, and safety workflows.
When industrial firms build an LLM model tuned to manuals and logs, technicians can access repair steps faster and reduce downtime.
Example: Digital twin systems pair LLM agents with machine data to support troubleshooting and predictive maintenance.

What is the Cost Of Developing LLMs & Time Required?
Most real-world LLM projects require a cost estimation of $30,000 and $450,000 or more, depending on whether you fine-tune a pretrained model or build a more specialized version.
Developing an LLM requires careful planning because both cost and timeline vary based on model size, training depth, and the approach your team chooses.
Timelines range from a few weeks to over a year, based on dataset preparation, GPU access, and alignment needs. Understanding these ranges helps teams plan costs to create AI apps or LLM models, avoid training delays, and stay realistic about what an LLM project truly demands.
|
Approach |
Typical Timeline |
Cost Estimate |
Notes |
|
Buy / Hosted LLM |
1–4 weeks |
$1,000–$10,000 yearly |
Subscription only; no training or infra needed |
|
Fine-Tune Pretrained Model (7B–34B) |
1.5–3 months |
$30,000–$180,000 |
Includes dataset cleaning, GPU hours, and tuning cycles |
|
Fine-Tune Larger Models (34B–70B) |
2–4 months |
$180,000–$450,000 |
Costs rise with model scale, alignment, and dataset size |
|
Advanced or Specialized Custom Training |
4–9 months |
$450,000 or more |
Used for regulated sectors or deep domain learning |
Factors Affecting Cost and Timeline
Several factors exist that impact the cost and timeline when planning to build an LLM model. These include:
► Dataset Quality
The condition of your data strongly affects both cost and time. Clean, structured text speeds up development, while unstructured or sensitive datasets require deeper cleaning, review, and validation.
► Model Size
Larger models demand more compute and longer training cycles. This increases development time and requires more engineering oversight to maintain training stability.
► Engineering Effort
The amount of work needed to prepare data pipelines, manage training runs, and fix issues during development has a direct impact on timelines. More iterations lead to extended schedules.
► Alignment and Safety
Models that must follow strict behavior, safety rules, or compliance standards take longer to tune and test, especially in regulated industries.
► Deployment Requirements
Private cloud, hybrid, or on-prem environments add extra setup and testing, which extends the overall project duration.
Selecting the Right LLM Strategy: Buy, Fine-Tune, or Build From Scratch
When teams begin planning how to build an LLM model, they typically come across three strategic routes: buying a hosted model, fine-tuning an open source backbone, or creating an LLM model from scratch.
Each option offers tradeoffs in control, cost, data governance, and technical effort.
|
Criteria |
Buy Hosted LLM |
Fine-Tune Pretrained Model |
Build From Scratch |
|
Model Control |
Very low; architecture and weights are fully vendor-managed |
Moderate; control over tuning, behavior, and domain adaptation |
Full architectural control, custom tokenizer, training rules, model depth |
|
Infrastructure Load |
None; all computing handled by the provider |
Moderate; requires GPU nodes for fine-tuning and inference |
Very high; distributed training clusters, storage, and orchestration |
|
Data Governance |
Limited; data flows through external APIs |
High; can run models in private or on-prem environments |
Maximum; data never leaves internal infrastructure |
|
Optimization Flexibility |
Minimal; limited to prompt engineering |
High; LoRA, QLoRA, SFT, RLHF, DPO, adapters |
Highest optimization possible at the architecture, training objective, and token level |
|
Technical Expertise Needed |
Low; mainly integration skills |
Medium: MLOps, model tuning, and data engineering |
Highly skilled research engineers, infra specialists, and large-scale training expertise |
|
Cost Profile |
Predictable subscription costs |
Moderate compute + engineering cost |
Very high; GPUs, training cycles, and talent |
|
Ideal Use Cases |
Chatbots, content tools, rapid prototyping, and general NLP tasks |
Domain agents, internal tools, compliance workflows, and regulated industries |
Proprietary AI IP, sensitive datasets, specialized reasoning, large enterprise systems |
When to Choose Which Strategy?
You can further hire dedicated developers who can better guide you about these models and help select one. Also, refer to the below summarization of the models that can help you get a clear understanding.
-
You can plan to buy Hosted LLM services when your priority is fast deployment, minimal engineering, and predictable API costs. Vendor-hosted models fit cases like conversational agents, content tools, and early-stage experimentation where deep customization or model transparency is not required.
-
Picking Fine-Tuning Pretrained Models is the most balanced route. It works when you need domain-level accuracy, internal hosting, or policy-aligned behavior. Using models like Llama, Mistral, or Gemma with techniques such as LoRA, QLoRA, RLHF, or DPO lets teams adapt behavior without full-scale training. It suits companies that need private deployment with manageable compute demands.
-
Building From Scratch is chosen when organizations aim to develop an LLM model with complete control over architecture, vocabulary, tokenization, and training signals. It is ideal for enterprises handling sensitive datasets or needing unique performance characteristics that off-the-shelf models cannot offer.
Challenges & Potential Solutions To Build Productive LLM Models
Simply focusing on the steps to develop an LLM model is not enough. But along with such potential challenges in developing LLM models needs to be taken care of.

Below are the most common challenges teams face when they build an LLM model, along with practical ways to solve them.
Challenge 1: High Computing and Infrastructure Costs
Training and fine-tuning large models need powerful GPU clusters, fast networking, and large storage. These costs grow with longer training cycles and bigger architectures, which often push budgets beyond early estimates.
Solution: Teams can reduce cost by using parameter-efficient methods like LoRA or QLoRA, cloud GPU rentals, mixed precision training, and checkpointing. Choosing smaller backbones or distilled variants also helps control spending.
Challenge 2: Data Quality and Availability Issues
LLMs need huge amounts of well-curated text, but many businesses lack clean, domain-rich datasets. Poor quality data leads to hallucination, weak reasoning, or unwanted bias.
Solution: A strong data pipeline with preprocessing, filtering, annotation, and synthetic sampling improves dataset value. Involving domain experts during review increases accuracy for fields like medicine, finance, or law.
Challenge 3: Alignment, Safety, and Bias Risks
Models may generate false information, unsafe phrasing, or biased responses if alignment is weak. This creates trust issues and regulatory risks for enterprises.
Solution: Supervised fine-tuning, RLHF, policy alignment, toxicity filtering, and continuous feedback loops to improve safety. Refusal training and controlled behavior shaping also help reduce harmful output.
Challenge 4: Long Development Timelines
Teams often ask how long does it takes to build an LLM because training cycles, debugging, retraining, and dataset changes extend timelines significantly.
Solution: Starting with pretrained models speeds progress. Automated experimentation, scalable pipelines, synthetic data generation, and multi-run scheduling help move from prototype to deployment faster.
Challenge 5: Deployment and Scaling Challenges
Once trained, large models are expensive to run and slow to serve at scale. They also need monitoring, security layers, and version management.
Solution: You can hire AI developers and adopt optimization techniques like quantization, distillation, caching, and hardware acceleration to improve inference speed. Further, Observability tools, access controls, encrypted storage, and logging ensure stable and safe production use.

How JPLoft Can Help With LLM Development?
JPLoft helps businesses build, refine, and deploy Large Language Models in a way that feels structured, predictable, and aligned with real goals. As an experienced LLM development company, our team supports you from the earliest planning steps to live deployment. We start by helping you choose the right model strategy, whether it involves buying, fine-tuning, or building a more specialized version.
Once the direction is clear, we assist with data preparation, model selection, and training setup. Our engineers handle fine-tuning, safety alignment, optimization, and evaluation so your model performs well in real-world conditions. For companies working with sensitive or high-value data, we also provide private deployment, on-prem setup, and controlled access environments.
JPLoft’s approach focuses on building LLMs that are accurate, safe, and efficient to run. We guide teams through experimentation cycles, help resolve training issues, and offer continuous improvements as behavior goals change. With technical expertise and hands-on support, we make LLM development more practical and achievable for organizations of all sizes.
Conclusion
Building an LLM may seem complex at first, but it becomes far more manageable when the process is broken into clear stages. Each step, from defining the purpose to preparing high-quality data and training the model, plays an important role in shaping how well the system performs.
Many teams today want to understand how to build an LLM model so they can improve automation, strengthen decision support, or create better user experiences. The key is choosing the right direction, whether that means fine-tuning an existing backbone or developing a more tailored version that fits your domain.
Training, alignment, and evaluation add the final layers of confidence and help create a model that behaves safely and reliably. With careful planning, the right technical choices, and ongoing monitoring, your organization can create an LLM that delivers consistent value and continues to learn over time.
FAQs
If you are concerned about “how to build an LLM model”, then you should start by defining the objectives, building a high-quality dataset, planning for the backend, training the model, evaluating the model, and preparing it for deployment.
The timeline depends on the project size. Fine-tuning a small model usually takes a few weeks, while deeper training or domain-specific systems may take several months. Time increases when datasets need cleaning or when safety alignment is required.
Fine-tuning works well when you need domain accuracy without high compute costs. Building a custom LLM is useful when you need full control, unique behavior, or strict privacy, but it requires much more time and resources.
To build an LLM model, you need clean training data, a base architecture like Llama or Mistral, GPU compute, and a clear plan for training, tuning, and safety alignment. You also need tools for evaluation and a deployment setup to run the model in real use.
LLMs stay safe through alignment steps like instruction tuning, behavior rules, and repeated testing. Developers check for harmful outputs, bias, and incorrect claims, then fine-tune the model until it behaves consistently and follows set guidelines.

Rahul Sukhwal is the CEO and Founder of JPLoft, a visionary technologist with 18+ years at the forefront of emerging tech innovation and software engineering. He channels deep software engineering and AI expertise into building smarter, scalable solutions that shape how forward-thinking businesses worldwide harness the true power of AI.




Share this blog