






As futurist Ray Kurzweil once said, “Speech recognition is the gateway to seamless human-computer interaction.”
It is becoming even stronger with the help of artificial intelligence.
In a world where communication is key, AI speech recognition technology is revolutionizing the way we interact with machines.
From voice assistants like Siri to groundbreaking medical transcription software, AI-driven speech recognition is changing the game across industries.
When properly trained, modern AI-powered systems can deliver over 90% accuracy in understanding conversational speech.
Many aspiring entrepreneurs and investors think this is a great opportunity to build an AI speech recognition technology.
Well, that’s completely true.
Keeping that in mind, if you are on this blog to learn about AI speech recognition system, then let us help you with complete information.
What is AI Speech Recognition Technology?
AI speech recognition technology is the brain behind machines that understand and respond to human speech.
It uses artificial intelligence to convert spoken language into text and even interpret meaning, tone, and intent.
From Amazon Alexa answering your questions to Google Assistant translating languages in real time, speech AI is everywhere.
Speech Recognition System Market Stats
The voice tech revolution is already underway, and it’s only getting louder.
From powering smart assistants to transforming customer service, the demand for AI-driven speech recognition systems is growing fast.
Let’s take a quick look at the numbers shaping the future of this booming industry:
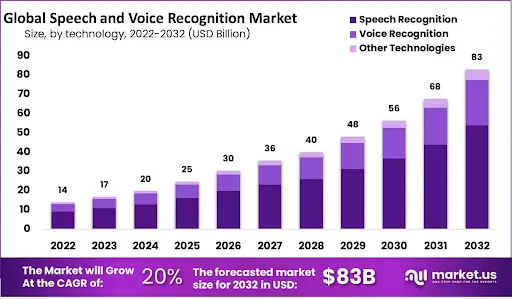
By 2032, the global speech and voice recognition market is expected to reach USD 83.0 billion in revenue.
In 2023, the market was valued at USD 17.0 billion, with:
-
- Speech recognition contributes USD 11.1 billion.
- Voice recognition contributes USD 4.8 billion.
- Other technologies adding USD 1.1 billion
Cloud-based deployment dominates the space, owning 59% of the total market share.
The United States stands as the global leader in speech recognition, with revenues reaching USD 3039 million.
31% of voice tech users view cleanliness as a major benefit of voice interaction, especially in touch-free environments.
81% of businesses in customer service have adopted voice technology to enhance user experience and streamline operations.
These numbers make one thing clear: there’s never been a better time to create an AI app that taps into the power of speech recognition and shapes the future of user interaction.
Difference Between Speech Recognition and Voice Recognition: Are They Same?
While many people use speech recognition and voice recognition interchangeably, they actually refer to two different technologies, both powered by AI but with distinct purposes.
Speech recognition focuses on understanding what you say, converting spoken words into text. Voice recognition, on the other hand, is about identifying who is speaking, using voice patterns as a biometric identifier.
Here's a quick comparison to make it crystal clear:
|
Feature |
Speech Recognition |
Voice Recognition |
|
Purpose |
Converts spoken language into text |
Identifies and verifies the speaker’s identity |
|
Primary Use |
Voice typing, virtual assistants, transcription |
Security systems, personalized responses |
|
Focus |
Understanding words and phrases |
Recognizing voice characteristics |
|
Technology Type |
Natural Language Processing (NLP) based |
Biometric identification |
|
Examples |
Siri understands commands, and automated captions |
Alexa recognizing different family members |
|
User Intent |
"What are you saying?" |
"Who is speaking?" |
So, while both fall under the umbrella of AI in speech technologies, they serve different needs.
If you’re thinking about building an app that uses both speech and voice recognition, it’s smart to get a clear idea of the cost to develop an AI app like that.
It helps you plan better and avoid surprises down the road. Need help breaking it all down? Let’s create something amazing together.

Advantages of an AI-powered Speech Recognition System
Integrating Artificial Intelligence in Speech Recognition Systems isn’t just about modernizing tech; it’s about unlocking smarter, faster, and more inclusive experiences.
Here are the top benefits that are reshaping the way users and businesses engage with technology, giving you more reasons to develop an AI speech recognition technology:
1. Faster and Hands-Free Interaction
With AI-powered Speech Recognition Systems, users can perform tasks 3x faster than typing.
This hands-free experience boosts efficiency in mobile apps, smart homes, and in-car systems,ideal for multitasking or on-the-go productivity.
In fact, voice commands are expected to handle 50% of all smartphone searches by 2025.
2. Improved User Accessibility
AI-driven speech tools are opening digital doors for millions.
Around 1.5 billion people globally live with some form of hearing, vision, or mobility impairment.
Speech Recognition AI Systems empowers these users through real-time transcriptions, voice commands, and multilingual support, making your app more inclusive and regulation-compliant.
3. Increased Operational Efficiency
Businesses using AI speech tools report up to 40% faster customer query resolution.
AI-enabled Speech Recognition Systems automate call summaries, note-taking, and voice-driven actions, freeing up human agents and improving accuracy.
This not only cuts time but also enhances CX across support, sales, and service teams.
4. Highly Scalable and Adaptive
Modern speech recognition systems can now achieve over 90% accuracy in natural conversations when properly trained.
With Artificial Intelligence in Speech Recognition Systems, your app can scale globally, learning accents, local phrases, and context over time, without manual reprogramming.
Perfect for growing startups and enterprise-level deployments alike.
5. Cost Savings Over Time
By replacing manual processes and reducing the need for live agents, businesses save big.
Companies integrating Artificial Intelligence in Speech Recognition Technology report an average 25–30% reduction in operational costs.
From transcription automation to smart voice assistants, AI transforms your budget while enhancing user satisfaction.
How AI Speech Recognition Overcomes Traditional System Limitations?
Traditional speech recognition systems were limited, often struggling to understand natural human speech.
But AI-based speech recognition systems have stepped in to solve many of these problems.
Let's dive into some of the major challenges in the old systems and see how AI-powered speech recognition technology is changing the game.
1] Limited Accuracy in Noisy Environments
In traditional systems, background noise was a huge issue.
Whether it’s the hum of a busy office or street noise, the system often couldn’t make out your words.
AI-based speech recognition systems solve this by using advanced Noise Cancellation Technology to filter out unwanted sounds and focus on your voice.
Now, even in noisy places, AI-powered speech recognition technology can hear you loud and clear.
2] Struggling with Accents and Dialects
Old systems weren’t great at understanding different accents or dialects.
A British accent might confuse a traditional system, and regional phrases were often misunderstood.
But with AI-powered speech recognition technology, the system gets smarter.
It learns from a wider range of speech patterns, making it much better at understanding diverse accents and dialects, no matter where you're from.
3] Lack of Context Understanding
Traditional systems could only pick up on individual words, without understanding the context.
So, if you said "book a table," the system might misunderstand what you mean.
AI-based speech recognition systems fix this with Natural Language Processing (NLP).
They don’t just hear the words; they understand the meaning behind them, allowing for more accurate and relevant responses.
4] Slow and Limited Response Times
Earlier speech recognition systems were slow and often didn’t recognize speech in real-time.
This created frustrating delays when trying to use voice commands or dictate text.
Thanks to AI-powered speech recognition technology, systems are now faster and more efficient.
They process speech in real-time, offering quicker and smoother interactions with no delays.
5] Inability to Personalize Interactions
Traditional systems treated everyone the same, unable to adapt to individual users.
This made the experience less personal and effective.
Now, with Speaker Recognition technology, AI-based speech recognition systems can identify who’s speaking and adjust responses accordingly.
This makes interactions more personalized and tailored to each user.
6] Difficulty with Complex Sentences
Older systems would trip over complex or compound sentences, often failing to capture the meaning.
They could handle simple commands, but when it came to more detailed instructions, they struggled.
AI-powered speech recognition technology tackles this by using advanced Language Models to predict and understand longer, more complex sentences.
Now, you can speak naturally, and the system keeps up with you.
7] Poor Adaptability to Different Use Cases
Traditional systems were designed for basic tasks and couldn’t adapt to specialized use cases, like medical transcription or legal jargon.
AI-based speech recognition systems solve this by learning from large, diverse datasets.
Be it a technical field or casual conversation, AI-powered speech recognition technology can be trained to handle specific terminology and adapt to different contexts.
Thanks to these advancements, AI speech recognition systems are far superior to traditional systems.
They’re faster, smarter, and much better at handling the complexities of human speech, making everyday tasks more efficient and intuitive.
How to Build an AI Speech Recognition System?
Building a voice AI system isn’t just about tech; it’s about designing for human experience.
To integrate AI in speech recognition, you need to mix machine learning expertise, real-world data, and scalable infrastructure.
Whether you're designing it for virtual assistants, smart homes, or transcription apps, the process can be both technical and exciting.
Here’s your step-by-step guide to know how to create an AI speech recognition technology that’s smart, scalable, and ready for users.
Step 1: Define the Use Case
Before you start to develop an AI speech recognition system, clarify its purpose.
Are you building a voice assistant, an AI note-taker, or a speech-to-text app for healthcare? This step helps you choose the right models, datasets, and features.
Each use case has unique requirements, real-time response, high accuracy, or multilingual support and defining them early saves time, effort, and cost during development.
Step 2: Collect and Prepare Voice Data
To create an AI speech recognition system that works well, your model needs voice data lots of it.
Gather recordings across genders, age groups, accents, and environments. Also, include background noise in some files to improve real-world performance.
Once collected, transcribe and label the data accurately.
The better your training data, the more intelligent and adaptable your model will be. Clean, diverse, and labelled datasets are the backbone of voice AI.
Step 3: Choose the Right ML Framework
Choosing the right tools is essential when you build an AI speech recognition system.
Frameworks like TensorFlow, PyTorch, and Kaldi offer libraries and APIs tailored for audio and speech processing.
These frameworks help you implement models like CNNs, RNNs, or transformers.
They also let you integrate with APIs like Hugging Face or OpenAI Whisper for faster prototyping and deployment.
Step 4: Train with Acoustic and Language Models
Speech recognition requires more than just audio detection; you also need comprehension.
When you develop an AI speech recognition technology, you train acoustic models to identify phonemes and patterns in audio, while language models provide contextual understanding.
Training both together gives your system the ability to not only hear but understand the speaker accurately. It’s what separates smart assistants from frustrating ones.
Step 5: Implement Speech-to-Text (STT) Engine
This is the heart of your system.
Use cloud services like Google Speech API or open-source engines like DeepSpeech to create an AI speech recognition technology that turns speech into usable text.
Customize it to your domain, for example, legal, medical, or customer support to improve relevance and reliability.
Your STT engine determines how smoothly the speech interface works for end-users.
Step 6: Optimize for Noise and Real-Time Output
No one wants delayed responses or errors in loud places.
When you build an AI speech recognition system, you must integrate signal enhancement tools like automatic gain control, echo cancellation, and noise suppression.
Additionally, reduce latency with lightweight models or edge processing so users experience immediate feedback essential for voice search, gaming, or real-time translation.
Step 7: Test with Real Users and Iterate
You’ve trained the model, but now you need to see how it performs in the wild.
Conduct usability testing in various environments and with diverse user groups.
As you develop an AI speech recognition system, keep refining it based on real feedback and behaviour.
The best AI systems are those that continuously learn and improve with usage over time.
Step 8: Deploy and Scale Your System
Once confident in performance, deploy your AI voice engine to web apps, mobile apps, or IoT devices.
Use APIs for easy integration and cloud services for scalability.
As you create an AI speech recognition system, make sure it’s scalable, secure, and easy to update. Monitor performance and keep optimizing as you grow your user base.
So, we believe you got an idea about how to develop an AI speech recognition system.
Technologies Behind Building an AI-Based Speech Recognition System
Ever wondered how your voice assistant understands you so well? Or how Google transcribes your speech so accurately? That’s the magic of AI-based speech recognition systems!
These systems use a blend of smart technologies to turn your spoken words into meaningful actions.
If you're looking to create an AI speech recognition system like Siri or Alexa, it’s essential to understand how these core technologies work together to make everything run smoothly.
1. Natural Language Processing (NLP)
NLP is like the brain of your voice assistant.
It helps the system understand what you're actually saying, not just what you're saying.
Without it, AI-powered speech recognition technology would only hear sounds without grasping the meaning behind them.
With NLP, your AI can understand everything from complex sentences to simple commands, even if you use slang or speak with an accent.
This technology is important to develop an AI speech recognition system that truly comprehends complex sentences or commands.
2. Acoustic Models
Think of Acoustic Models as the AI’s “ear.”
They break down the sounds you make into recognizable patterns.
These models help the system understand how different sounds form words.
Even if there’s noise in the background, AI-based speech recognition systems can still figure out what you're saying.
3. Deep Learning and Neural Networks
Deep Learning is like teaching the system to "learn" from experience.
It uses Neural Networks to find patterns in speech, as a human brain would.
As you create an AI speech recognition system, this enables the system to improve with more data, allowing it to understand various voices, accents, and speech speeds.
This makes AI-powered speech recognition technology smarter and more accurate over time.
4. Speech Signal Processing
Before the system can understand you, it has to process the signal.
This means breaking down sound waves and figuring out the key parts of your speech.
By Speech Signal Processing, the system turns your voice into something it can work with.
It helps AI-based speech recognition systems focus on the important parts, even if the environment is noisy.
5. Language Models
Language Models help the system predict what you’re going to say next.
By understanding how words fit together, they make the recognition process smoother.
This technology ensures that AI-powered speech recognition technology doesn't just understand the individual words but the context behind them.
It helps fix mistakes and improve accuracy, especially when you're speaking fast or unclearly.
6. Noise Cancellation Technology
Imagine trying to talk to your assistant in a crowded cafe.
Without Noise Cancellation, your assistant might misunderstand you.
This technology helps AI-based speech recognition systems focus only on your voice, blocking out all the extra noise.
It’s crucial when you create an AI speech recognition system that needs to function in real-world environments, ensuring clarity in every interaction.
7. Speaker Recognition
With Speaker Recognition, the system knows who is talking.
It can tell the difference between multiple people speaking, making your assistant more personalized.
For example, in smart homes, AI-powered speech recognition technology can recognize different voices and adjust responses accordingly.
It’s all about making the interaction feel more natural and tailored to you.
These technologies work together to make AI-based speech recognition systems powerful and efficient.
Cost to Develop an AI Speech Recognition System
When it comes to developing an AI speech recognition system, the cost can vary significantly based on the system's complexity.
The price depends on various factors, including features, platform, and technology stack.
A basic voice recognition system may cost a few thousand dollars, ideal for simple applications.
Overall, the cost to create an AI speech recognition system can go from $5,000- $300,000+.
However, if you're aiming for advanced capabilities like Natural Language Processing (NLP), real-time speech processing, and multi-language support, costs can soar to tens of thousands.
Additionally, ongoing training, model updates, and integration into multiple platforms add to the total price. The more sophisticated your needs, the higher the investment!
|
Feature/Component |
Estimated Cost |
Details |
|
Basic Voice Recognition |
$5,000 - $15,000 |
For simple speech-to-text applications with limited features. |
|
Advanced NLP & Speech Processing |
$20,000 - $50,000 |
Includes Natural Language Processing for better accuracy and context. |
|
Multi-language Support |
$10,000 - $30,000 |
Adding support for multiple languages increases development time and cost. |
|
Real-time Speech Processing |
$15,000 - $40,000 |
Enables real-time transcription and command processing. |
|
Data Collection & Model Training |
$15,000 - $50,000 |
Gathering data and training the models to recognize different accents. |
|
Platform Integration (iOS/Android) |
$10,000 - $30,000 |
Platform-specific development for mobile and web apps. |
|
Ongoing Maintenance & Updates |
$5,000 - $20,000 annually |
Continuous model improvements and bug fixes. |
This breakdown helps to understand how the cost to develop an AI speech recognition system can scale based on the features and complexity involved.
Use Cases of AI in Speech Recognition Systems
Let’s be honest, talking is easier than typing.
Whether you want to develop an AI speech recognition system or scale an enterprise product, AI augments speech recognition technology to make your app smarter, faster, and more human.
Here are some exciting real-world use cases you can tap into:
► Virtual Assistants & Smart Devices
Think Siri, Alexa, or Google Assistant, but custom-built for your brand.
If you're investing in virtual assistant app development, AI-powered speech recognition systems can help users manage tasks, schedule meetings, shop online, or interact with your services, just by speaking.
AI in speech recognition enables these apps to process natural conversation, making the user experience smooth, hands-free, and highly intuitive.
► Healthcare Dictation & Medical Transcription
Doctors don’t have time to type, especially during patient consultations.
With healthcare app development services, you can embed AI speech recognition technology to transcribe clinical notes, prescriptions, and patient interactions in real time, accurately and securely.
This streamlines workflows, reduces manual errors, and frees up doctors to focus more on care than documentation, all thanks to AI-augmented speech recognition technology.
► Customer Support Automation
Nobody enjoys waiting on hold or pressing “1 for support.”
Using speech recognition systems, you can automate voice interactions, route calls, or deploy AI voicebots that answer questions instantly and naturally.
AI in speech recognition allows your app to offer smart, conversational support, reducing ticket volume and improving customer satisfaction without compromising on quality.
► eLearning & Accessibility Tools
Learning gets a boost when voice comes into play.
By leveraging education app development services, you can add speech recognition AI features like voice-activated navigation, real-time lecture transcription, or oral quizzes to your app.
It’s especially valuable for users with disabilities or students learning in different languages. This is where AI augments speech recognition technology to make learning more accessible and engaging for everyone.
► Legal Transcriptions & Courtroom Reporting
In legal settings, accuracy isn’t optional; it’s critical.
A trusted lawyer app development company can help you integrate speech recognition AI into tools that transcribe courtroom dialogue, client meetings, and legal dictations with high precision.
It saves hours of manual work and ensures nothing gets lost in translation, making AI in speech recognition a powerful ally for legal tech solutions.
► Voice-Driven Apps for Logistics & Field Services
Your workforce is always on the move, and they need tools that keep up.
With speech recognition systems, field agents and delivery teams can update tasks, log incidents, or get instructions using just their voice, even in noisy conditions.
AI in speech recognition ensures these voice interactions are fast, accurate, and hands-free, improving both safety and productivity on the ground.
Future Trends Shaping the AI Speech Recognition System
AI speech tech isn’t slowing down; in fact, it’s just warming up.
As more businesses race to add voice features into their apps, the future of AI in speech recognition looks bold, brilliant, and borderline sci-fi.
From real-time emotion detection to hyper-personalized voicebots, the possibilities are wild and wildly useful.
If you’re looking to create a speech recognition AI technology that’s built to last, keep your eyes on these forward-thinking trends:
1. Multilingual and Accent-Adaptive Models
Say goodbye to language barriers.
Modern speech recognition systems are learning to understand not just multiple languages, but regional dialects and heavy accents too. This makes voice interfaces truly global and far more inclusive.
Expect apps that can seamlessly switch between Hindi, Spanish, English, or Arabic without skipping a beat.
2. Emotion-Aware Speech Recognition
Your voice says more than just words; it conveys how you feel.
Next-gen AI in speech recognition is evolving to detect tone, mood, and sentiment in real time.
Imagine a virtual assistant that knows when you're frustrated or a support bot that shifts its tone based on your stress level.
This makes interactions not only smart but also emotionally intelligent.
3. On-Device and Edge AI Processing
Latency is the enemy of smooth voice interactions.
But thanks to edge computing, we’re no longer relying solely on cloud-based models.
More and more speech recognition AI is now running directly on your device, making interactions faster, more secure, and perfect for low-connectivity environments.
This shift is a game-changer for virtual assistant apps, logistics tools, and any real-time voice interface, and it’s driving demand for smarter, on-device AI app development services like never before.
4. Integration with Generative AI
What if your speech interface could not only listen but also think?
By combining speech recognition systems with generative AI like ChatGPT, apps can now have deep, dynamic conversations.
Think voice-enabled tutoring apps, therapy bots, or smart sales assistants that don’t just respond, they engage.
This is the secret sauce for building ultra-intelligent, voice-first applications.
5. Privacy-First Speech Recognition
As voice data grows, so do concerns about how it's stored and used.
Future-ready developers are prioritizing privacy by building AI speech recognition technology with encrypted voice processing, local data handling, and user-first consent policies.
If you're planning to develop an AI speech recognition technology, this is a must-have trend, not just for compliance, but for trust.
6. Cross-Platform Voice Experiences
Users don’t want to restart their voice interaction just because they switched from phone to tablet to car.
The future lies in unified, cross-platform speech recognition AI where conversations follow you across devices. Think: starting a query on your smartwatch and finishing it on your home assistant without interruption.
This makes voice interfaces feel less like features and more like companions.
How Can JPLoft Help You Create a Speech Recognition Technology?
Ever wondered what it takes to turn a simple voice command into seamless action? That’s where the magic begins and where JPLoft steps in.
As a top-tier speech recognition software development company, we specialize in transforming futuristic ideas into a functional, voice-powered reality.
Whether you're building a smart assistant, voice-controlled app, or custom AI interface, our team knows how to blend algorithms, UX, and language models into one powerful solution.
We don’t just help you create a speech recognition technology; we help you lead the conversation. With us, your voice-first product won’t just work, it’ll wow.
Ready to make your app speak volumes?

Conclusion
The journey to build an AI speech recognition technology, as championed by visionaries like Ray Kurzweil, is a testament to the power of seamless human-computer interaction.
From overcoming challenges like background noise and diverse accents to meticulously defining use cases and training sophisticated models, the process demands both technical prowess and a user-centric approach.
The advantages are clear: faster, hands-free interactions, improved accessibility for millions, increased operational efficiency for businesses, and significant cost savings.
As we look ahead, the field is poised for even greater advancements with multilingual capabilities, emotion-aware systems, and privacy-first designs.
Embracing these trends is key to developing AI speech recognition that not only functions but truly revolutionizes how we interact with the digital world.
FAQs
Modern AI-powered speech recognition systems, when properly trained on diverse datasets, can achieve over 90% accuracy in understanding conversational speech.
AI utilizes sophisticated techniques like noise suppression algorithms, signal processing filters, beamforming, and spectral subtraction to effectively separate a speaker's voice from ambient noise, making the system reliable in various environments.
The key stages involve defining the use case, collecting and preparing voice data, choosing the right machine learning framework (e.g., TensorFlow, PyTorch), training acoustic and language models, implementing a Speech-to-Text (STT) engine, optimizing for noise and real-time output, testing with real users, and finally, deploying and scaling the system.
Yes, AI addresses this by training models on large, diverse datasets that include speakers from various regions and linguistic backgrounds. Unlike traditional rule-based systems, AI continuously adapts and evolves to understand a wide range of accents and dialects.
Real-world applications include virtual assistants (like Siri and Alexa), healthcare dictation and medical transcription, customer support automation (voicebots), eLearning and accessibility tools, legal transcriptions and courtroom reporting, and voice-driven apps for logistics and field services.

Rahul Sukhwal is the CEO and Founder of JPLoft, a visionary technologist with 18+ years at the forefront of emerging tech innovation and software engineering. He channels deep software engineering and AI expertise into building smarter, scalable solutions that shape how forward-thinking businesses worldwide harness the true power of AI.


Share this blog